
Intent Categorization in Multilingual Messages: Challenges and Solutions
Managing multilingual customer messages is complex but crucial for global businesses. Here's the challenge: messages come in various languages and platforms (email, social media, live chat), each with unique linguistic structures and cultural nuances. Without automation, sorting through these manually slows response times and frustrates teams.
Key insights:
- Intent categorization identifies the purpose of messages (e.g., complaints, inquiries).
- Multilingual AI tools like mBERT and XLM-RoBERTa streamline this process by recognizing patterns across languages.
- Challenges include:
- Structural differences between languages (e.g., English vs. Arabic).
- Limited data for less common languages (e.g., Swahili).
- Mixed-language inputs (e.g., code-switching).
- Solutions involve:
- Pre-trained multilingual models.
- Data augmentation (e.g., back-translation).
- Embedding models for better intent prediction.
Tools like Inbox Agents integrate these solutions into a unified messaging platform, automating categorization, routing, and response generation. This improves efficiency, reduces costs, and ensures faster, more accurate responses for global customers.
Intent Model, Real-Time Language Detection & Translations | Conversational AI Cloud by CM.com
Challenges in Multilingual Intent Categorization
Accurate intent categorization becomes significantly more complex in multilingual contexts. AI systems face hurdles like variations in language structure, limited data for certain languages, and the complexities of mixed-language communication. Let’s explore these challenges in detail: structural differences, resource disparities, and code-switching.
Language Differences and Structural Variations
Languages organize thoughts and meanings in unique ways. For example, English follows a Subject-Verb-Object pattern, so a typical customer complaint might say, "I cannot access my account." On the other hand, Japanese places the verb at the end of the sentence, while Arabic is read from right to left and comes with its own grammatical rules. These differences mean that the same intent - like asking for help with account access - can take entirely different forms depending on the language. AI systems must learn to recognize these patterns across languages.
Grammatical markers add another layer of complexity. For instance, Russian uses case endings to show relationships between words, while Chinese depends heavily on word order and context. Arabic, with its root-and-pattern system, creates multiple related words from a single root. Beyond grammar, cultural nuances also influence how people express intent, further complicating the task for AI models.
Resource Gaps Between High- and Low-Resource Languages
The availability of training data varies widely between languages, creating imbalances in AI performance. Languages like English - and to a lesser extent, Spanish, French, German, and Mandarin - benefit from rich datasets that improve intent categorization. In contrast, languages such as Swahili, Bengali, or Vietnamese often lack sufficient annotated data, making it harder to develop reliable models.
This imbalance becomes even more pronounced when dealing with regional language variants. For example, while Spanish and Portuguese are widely spoken, training data often focuses on their standard forms, leaving regional dialects underrepresented. Similarly, domain-specific language, like terminology in healthcare, finance, or technology, can exacerbate these gaps when specialized vocabulary is missing from datasets.
Code-Switching and Mixed-Language Input Problems
Code-switching - when speakers alternate between languages in a single conversation - is another challenge for AI systems. In the United States, it’s common to see messages blending English and Spanish, such as: "Hi, I need help with mi cuenta because I cannot log in." Here, the AI must process both languages and still identify the user’s intent correctly.
The use of technical terms further complicates things. Non-English speakers often integrate English technical vocabulary into their native language. For instance, a French customer might say, "Mon smartphone ne peut pas se connecter au WiFi", combining French structure with an English term. In multilingual communities, customers may mix heritage languages with English slang or formal business expressions. In customer service scenarios, where conversations may shift between languages as agents respond, maintaining context while ensuring accuracy becomes critical.
These challenges call for advanced AI solutions to improve intent categorization across languages. The next section will explore the specialized techniques needed to address these complex issues.
AI-Driven Solutions for Multilingual Intent Categorization
Modern AI technologies are breaking down language barriers, making multilingual intent recognition more accurate and efficient. Let’s dive into some of the key methods driving this progress.
Using Multilingual Pre-Trained Models
Multilingual pre-trained models have transformed cross-lingual understanding. These models are trained on vast datasets covering dozens of languages, allowing them to share knowledge across linguistic boundaries.
Take mBERT (multilingual BERT), for example. It’s trained on Wikipedia text from 104 languages, enabling it to recognize intent patterns across different languages - even when it hasn’t seen specific examples in a particular one. For instance, if mBERT learns to identify complaints in English and Spanish, it can often detect similar patterns in Portuguese or Italian without additional training.
Then there’s XLM-RoBERTa, which ups the ante by training on 2.5 terabytes of text from 100 languages. This model is particularly adept at handling structural differences between languages. For example, it can recognize that "Cannot login to account" in English and "No puedo acceder a mi cuenta" in Spanish express the same intent, despite differences in grammar and word order. By creating shared representations for similar concepts, XLM-RoBERTa enables high-resource languages like English to enhance performance for low-resource languages such as Bengali or Swahili. This shared understanding is a game-changer for multilingual AI systems.
These models provide a strong foundation, but data augmentation takes things even further.
Data Augmentation to Fill Resource Gaps
Data augmentation techniques are vital for addressing the lack of training data in underrepresented languages. They expand existing datasets, making AI systems more versatile.
One popular method is back-translation. This involves translating training data from a high-resource language into a target language and then back again. For example, the English sentence "I need help with billing" might be translated into French as "J'ai besoin d'aide pour la facturation" and then back to English as "I require assistance with invoicing." While the intent remains the same, the phrasing varies, enriching the training data.
Another approach is synthetic data generation, which creates entirely new examples based on existing patterns and linguistic rules. For instance, if you have examples of refund requests in English, synthetic generation can produce variations using different sentence structures, synonyms, or regional expressions. This is particularly useful for capturing local nuances and colloquial speech.
Finally, paraphrasing techniques generate multiple ways to express the same intent. A simple complaint like "My order is late" can be transformed into variations such as "My package hasn't arrived yet", "The delivery is overdue", or "I'm still waiting for my shipment." These variations help the model understand a wider range of expressions while staying focused on the same underlying intent.
While data augmentation enriches training datasets, advanced embedding models play a crucial role in understanding intent across languages.
Advanced Embedding Models for Intent Prediction
Multilingual sentence embeddings convert entire messages into numerical formats that capture their semantic meaning, regardless of the language. This allows AI systems to identify similar intents expressed in completely different words.
For example, Language-Agnostic BERT Sentence Embedding (LaBSE) supports 109 languages and can match intents like "Where is my order?" in English with "¿Dónde está mi pedido?" in Spanish, even though the two phrases share no common vocabulary. This capability is essential for businesses serving diverse, multilingual audiences.
Similarly, Sentence-BERT models are fine-tuned to detect semantic similarities. They excel at understanding mixed-language syntax and indirect expressions. For instance, while traditional keyword-based systems might miss the connection between "I'm having trouble getting into my account" and "cannot access my account", Sentence-BERT captures the semantic link, ensuring accurate categorization.
These models also enable cross-lingual semantic search, which identifies similar intents across languages. If a system has been trained to handle account lockout issues in English, it can apply that knowledge to recognize similar problems in German, Japanese, or Arabic. This significantly enhances the accuracy of responses for global customers.
sbb-itb-fd3217b
How Inbox Agents Solves Multilingual Intent Challenges
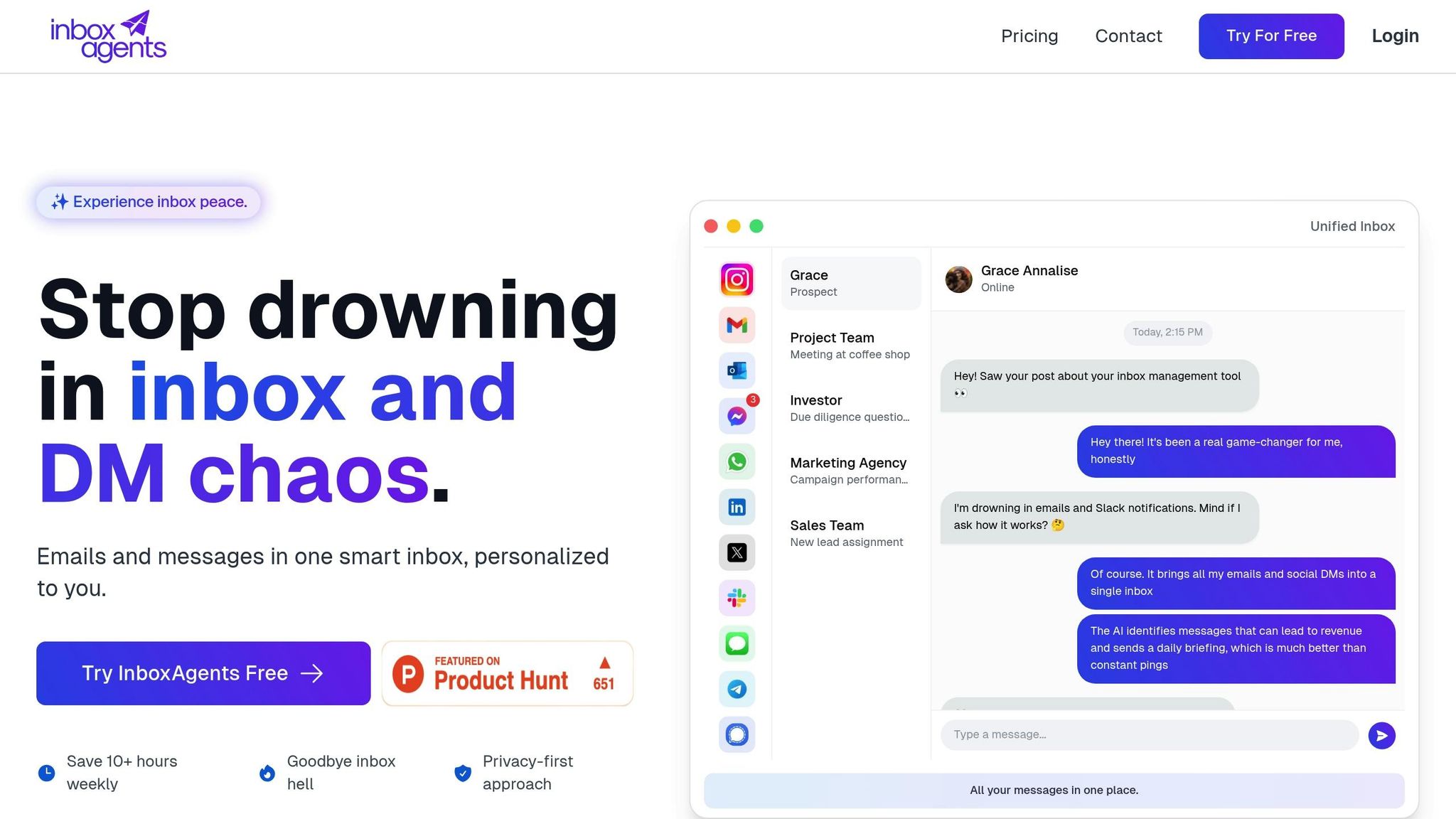
When it comes to recognizing multilingual intent, AI becomes truly impactful when combined into a cohesive platform. Inbox Agents tackles hurdles like differing language structures and code-switching by applying advanced AI models in practical ways. This approach bridges cutting-edge technology with everyday business needs, enabling accurate communication across languages.
Unified Inbox with AI-Powered Multilingual Features
Inbox Agents simplifies multilingual intent categorization by consolidating all messaging platforms into a single, unified interface. Whether it’s emails, chats, or social media messages, everything is managed in one streamlined dashboard.
With AI-powered automated inbox summaries, teams can quickly grasp the intent behind messages, no matter the language. For example, a customer service manager might see summaries that highlight urgent billing complaints in Spanish, product inquiries in French, and technical support requests in German - all automatically processed and categorized.
The platform also offers smart replies and negotiation handling, using pre-trained multilingual models to generate responses that respect both intent and cultural nuances. For instance, a formal inquiry in Italian will receive a suitably formal reply, ensuring professionalism across languages.
Personalized AI responses take it a step further by incorporating your business’s specific context. This means the system doesn’t just recognize a refund request - it understands your company’s refund policies, procedures, and preferred tone, delivering responses that align with your brand, no matter the customer’s language.
Thanks to real-time analysis, multilingual intent recognition happens instantly as messages arrive. There’s no waiting for batch processing or manual reviews. Whether the message is in English, Mandarin, or Arabic, the system immediately identifies its intent and routes it to the right team member or workflow.
Real-Time Analysis for Intent-Based Message Management
Real-time analysis enhances message handling by continuously extracting actionable insights from global customer interactions. For instance, the system might reveal that German customers often ask about product specifications before purchasing, while Brazilian customers focus more on delivery times. These insights help businesses fine-tune their communication strategies for different linguistic and cultural audiences.
The platform’s AI-powered message filtering and prioritization ensures urgent issues - like complaints or cancellations - are flagged immediately, regardless of the language. This prevents critical messages from being overlooked or lost among routine inquiries.
Team management features further streamline operations by assigning conversations based on both language skills and subject matter expertise. For example, a technical support query in Japanese is routed to a team member fluent in Japanese and knowledgeable about the product, ensuring accurate and effective responses.
Additionally, abuse and spam filtering safeguards businesses from multilingual spam campaigns and harmful content. This is especially crucial for companies operating in diverse markets, where spam patterns and abusive language can vary significantly across regions.
Conclusion
Global businesses face tough challenges when it comes to multilingual intent categorization. Differences in language structures, uneven resource availability, and the complexities of code-switching present obstacles that traditional systems often can't handle. But AI-driven solutions are stepping in to tackle these issues head-on. Tools like multilingual pre-trained models, data augmentation methods, and advanced embedding systems are changing the game.
The key to success lies in bringing these AI techniques together in a single, cohesive platform. For example, Inbox Agents uses AI-powered models to unify messaging channels and accurately identify customer intents across multiple languages. With features like real-time analysis, automated inbox summaries, smart replies, and personalized responses, businesses can handle customer communications more efficiently. These tools replace manual processes with scalable, automated operations that still respect the nuances of different languages and cultural contexts. The result? A smoother, more effective way to manage global customer interactions while staying adaptable to market demands.
FAQs
How do multilingual models like mBERT and XLM-RoBERTa help improve intent categorization across different languages?
Multilingual models such as mBERT and XLM-RoBERTa bring a new level of precision to intent categorization by tapping into datasets that span multiple languages. Their advanced transformer-based architectures allow them to grasp contextual nuances, making it possible to interpret subtle semantic variations across different languages.
What sets these models apart is their ability to perform cross-lingual transfer. By sharing linguistic knowledge during training, they become especially effective for languages with limited resources. This approach ensures more accurate and reliable intent detection, even when dealing with multilingual or code-switched messages.
What challenges do AI systems face with code-switching in multilingual messages, and how can they be solved?
AI systems often face challenges with code-switching, which happens when people switch between languages during the same conversation. This can cause problems like misunderstanding the speaker's intent, lower translation accuracy, and struggles with processing languages that lack extensive resources. A big part of the issue is that many AI models are trained mostly on single-language datasets, making it tough for them to handle these complex language shifts.
To tackle these issues, efforts are being made to develop specialized models that are better equipped for code-switching. This includes improving multilingual datasets by incorporating diverse, high-quality examples and using advanced methods like meta-embeddings to represent mixed-language inputs more effectively. These strategies aim to help AI systems interpret and respond more accurately to multilingual communication in real-world situations.
How does data augmentation address challenges in intent categorization for low-resource languages?
Data augmentation plays a crucial role in addressing the challenges of intent categorization for low-resource languages. One popular technique is back translation, where text is translated into the target language and then translated back into the original language. This process helps generate additional training data, broadening datasets and improving model accuracy.
Other strategies include paraphrasing, which rephrases sentences while maintaining their meaning, and noising, where small, controlled modifications are introduced to the data. Sampling is another approach that helps create diverse variations of training data. Together, these methods make AI models more adaptable and capable of understanding intent in languages with limited resources, boosting their overall effectiveness and reliability.