
Checklist for Reliable Cross-Platform Messaging
Most messaging failures are silent, and that’s why teams miss them until users complain.
If I had to boil this article down to a short audit, I’d check five things first: clear delivery targets, channel-by-channel fallback rules, shared message IDs, duplicate control, and live monitoring with retries and alerts. This is where real-time inbox monitoring becomes essential for maintaining visibility. The article’s core point is simple: a message system is only reliable if it can fail, recover, and still keep the thread and state intact.
Here’s the short version:
-
Define “delivered” before building
I’d track more than provider acceptance. For some flows, read matters more than delivered. -
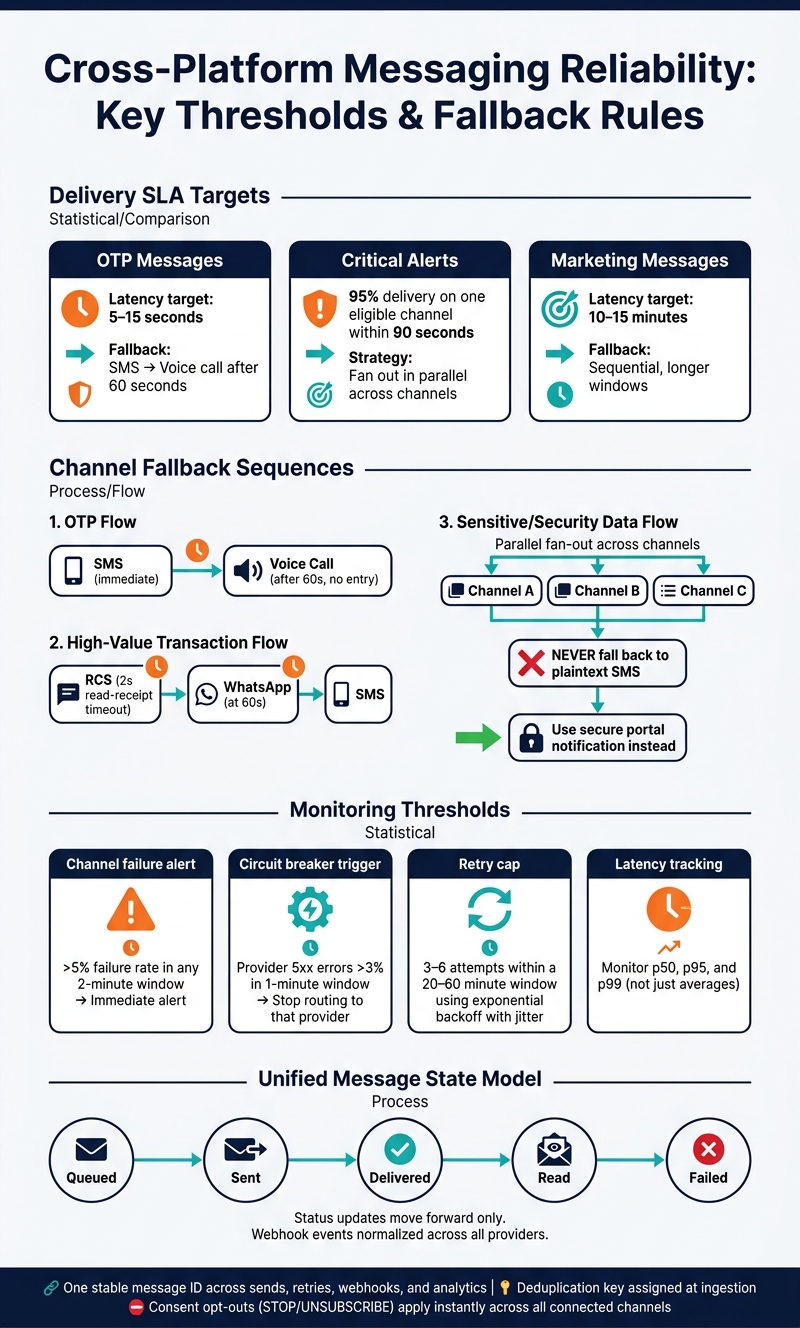
Set timing by message type
OTPs need 5–15 seconds. Marketing can wait 10–15 minutes. Critical alerts should hit 95% delivery on one eligible channel within 90 seconds. -
Use fallback rules that match risk
For example, OTPs can start with SMS and move to voice after 60 seconds. Sensitive data should not drop to plain SMS. -
Keep one message ID across the whole path
That means the same ID for sends, retries, webhooks, and reporting, with a dedup key to stop double sends. -
Centralize consent and suppression
For U.S. audiences, I’d make sure opt-outs like STOP and UNSUBSCRIBE apply across connected channels at once. -
Normalize status and retry behavior
Put events into one shared state model such as Queued, Sent, Delivered, Read, Failed. Retry transient errors like 429s with backoff and jitter. -
Watch hard numbers
Alert if channel failure goes above 5%. Open a circuit breaker if provider 5xx errors pass 3% in 1 minute. -
Test failure on purpose
Run outage drills, load tests, synthetic sends, and weekly DLQ reviews so fallback and retry paths don’t break when traffic spikes.
In other words: I wouldn’t trust a multi-channel setup just because messages can be sent. I’d trust it only if it can route, retry, switch channels, honor consent, and show one clean thread when things go wrong.
That’s the lens this checklist uses from start to finish.
Cross-Platform Messaging Reliability Checklist: SLAs, Fallbacks & Thresholds
Checklist Part 1: Define Reliability Requirements Before You Build
Before you touch routing logic, get clear on what “delivered” means. Don’t stop at platform acceptance. Measure delivery by receipt, render, and action. That distinction matters a lot.
For rich channels like WhatsApp or RCS, fallback decisions should use read receipts, not delivery receipts. That’s what tells you whether the message was actually seen, and it changes when your fallback logic should fire. From there, you can set routing thresholds, fallback timing, and retry rules with a lot more confidence.
Set Delivery Targets, Latency Limits, and Loss Tolerance
OTPs and marketing messages should not share the same SLA. They serve different jobs, so they need different targets.
Set a critical-alert target of 95% delivery through one eligible channel within 90 seconds. For timing, use 5–15 seconds for OTPs and 10–15 minutes for marketing.
Use at-least-once delivery with idempotent sends. In plain English: give each message a deduplication key at ingestion so failover and retries don’t create duplicates. Also set an alert for your team when failure rates on any single channel go above 5%.
Those numbers only hold up if the delivery path can fail over cleanly without sending the same message twice.
Map Channels, Message Types, and Failure Modes
Each channel breaks in its own way. SMS can get filtered by carriers. Push tokens expire. RCS isn’t available on every device. So don’t route by device type alone. Route by current client capability.
For example, check whether the active session supports rich media or end-to-end encryption before you choose a channel.
A few routing patterns make this concrete:
- For OTPs, send SMS right away and fall back to a voice call after 60 seconds with no entry.
- For high-value transactions, try RCS first with a 2-second read-receipt timeout, then WhatsApp at 60 seconds, then SMS.
- For security alerts, fan out in parallel across channels.
- Never fall back sensitive data to plaintext SMS. Use a secure portal notification instead.
Every route choice also needs to respect consent and content limits. A path that works on paper can still be off-limits in practice.
Document Consent and Compliance Rules for U.S. Audiences
Fallback logic has to follow consent rules. Before any message is sent, keep one unified inbox record of what each user agreed to receive, which channel it applies to, and the purpose of that consent.
For U.S. audiences, document TCPA and CTIA rules for SMS. That includes mandatory opt-out keywords like STOP and UNSUBSCRIBE for 10DLC and short-code traffic.
If a user opts out on one channel, that suppression should apply right away across all connected channels. Miss that handoff, and accidental policy violations become much more likely.
You should also configure quiet hours by U.S. time zone so messages don’t go out during restricted periods. And your consent records need enough detail to stand up to scrutiny. Store the source, timestamp, language, and opt-out options in a tamper-evident log.
Treat consent as part of reliability. If a fallback path isn’t allowed, it isn’t a valid delivery path.
sbb-itb-fd3217b
Checklist Part 2: Build a Redundant Delivery Path
Once the requirements are set, the next job is building redundancy into routing so one failure doesn’t snap the thread. The goal is simple: if a channel fails, the system should fail safely and still know exactly where the message is, what happened to it, and what should happen next.
Use a Central Orchestration Layer with Shared Message IDs
Give each message one stable ID when it’s created, then carry that same ID through sends, webhooks, retries, and analytics. That makes each message traceable and helps prevent duplicates. Use that same ID as the idempotency key for outbound sends and inbound webhooks, so retries and fallback moves don’t create duplicate messages.
The orchestration layer should also rely on a canonical message schema that stores intent, not channel-specific details. In plain English, the system should know what the message is trying to do before it decides how to send it. Separate adapters can then map that intent to the target channel, whether that ends up as an RCS rich card or plain-text SMS.
Before dispatch, resolve the user’s active endpoints and device capabilities so you only send formats the device can handle. That step matters more than it may seem. Sending a rich format to a device that can’t support it is like mailing a Blu-ray disc to someone who only owns a radio.
Define Fallback Sequences and De-Duplication Windows
Fallback should run in sequence, not in parallel, for single-recipient delivery flows. In other words, start with one channel, wait for the defined result, and only then move to the next. This approach is for one-to-one delivery paths, not broadcast messages or security alerts that may call for parallel sends. Start with the most cost-efficient channel, then move to the next option only if delivery or read status fails inside a set window.
That window shouldn’t be the same for every message type. Urgent messages need shorter fallback windows. Transactional and marketing messages can wait longer.
A simple rule of thumb:
- Urgent messages: use short windows
- Transactional messages: use moderate windows
- Marketing messages: use longer windows
Email plays a different role here. In transactional flows, use it as a copy, not as the event that triggers fallback.
Keep Conversation State in a Unified Inbox
The orchestration layer decides routing. The inbox preserves continuity.
Every channel event - sends, deliveries, reads, replies, and failures - should write to one central message journal. That journal should store message intent, channel, delivery status, and deduplication keys, so the full thread can be rebuilt no matter which transport carried the message.
When a message drops from RCS to SMS, label that change clearly so the thread shows what the user actually received. That sounds small, but it saves a lot of confusion later. If an agent sees an RCS card in the system while the user only got plain-text SMS, the follow-up can go sideways fast.
Mark downgrades clearly so agents and later follow-ups match the user’s actual experience.
These records then feed the retry and monitoring rules in Part 3.
Checklist Part 3: Monitor Delivery, Retries, and System Health
With routing and state already set up, the last step is keeping a close eye on delivery so you catch problems before users do. Monitoring is what keeps redundancy doing its job. Without it, issues can sit there for hours and no one notices.
Normalize Delivery Receipts and Error States
Map every provider event to Queued, Sent, Delivered, Read, or Failed before it hits dashboards or alerts, so every channel feeds the same inbox view.
Track accepted, delivered, read, replied, and failed states by channel in one shared model.
Retry transient errors like 429s. Stop on terminal errors like 401s or hard bounces.
Webhook events can show up out of order. That means status updates should only move forward.
Once you normalize statuses, retry logic can work from clean, consistent signals instead of provider-specific noise.
Use Smart Retries, Health Checks, and Synthetic Messages
For transient failures, use exponential backoff with jitter - randomized delays between retry attempts. This helps you avoid a retry storm, where workers all slam a recovering provider at the exact same moment after an outage. Cap retries at 3–6 attempts inside a 20–60 minute window.
If a provider’s 5xx error rate goes above 3% in a 1-minute window, open a circuit breaker and stop routing traffic to that provider until it recovers. For latency, track p50, p95, and p99, not just averages. And if the delivery failure rate goes past 5% in any 2-minute window, alert right away.
Run synthetic transactions during low-traffic periods to check that the full delivery path still works across every active channel.
After you’ve instrumented the live path, test how the system handles failure on purpose.
Test Outages, Peak Load, and Cross-Channel Handoffs
Monitoring tells you something broke. Testing shows whether recovery actually works.
Failure injection is the most direct way to do that. Intentionally fail a share of provider calls in staging and confirm that fallback logic kicks in, retries fire the way they should, and handoff from one channel to another works as planned. Run outage drills for major infrastructure failures, like a CDN issue or network outage, to check resilient routing.
Peak-load tests matter just as much. Simulate traffic spikes - think Black Friday or a mass notification blast - to make sure your message queues can absorb the load without dropping messages or adding delivery lag that breaks time-sensitive flows.
Review your Dead Letter Queues (DLQs) every week. They show you which failures still slip past retry logic. Use those failures to tighten retry rules and improve routing decisions.
Conclusion: A Short Reliability Checklist Teams Can Reuse
Use this short checklist to audit a messaging system fast.
| Category | Checks |
|---|---|
| Requirements | Delivery targets, latency limits, message flow classification, U.S. consent and compliance rules |
| Redundancy | Centralized dispatcher, canonical message schema, idempotency keys, ordered fallback paths, duplicate suppression |
| Monitoring | Signed webhook checks, exponential backoff with jitter, dead-letter queues, circuit breakers, correlation IDs, real-time health dashboards |
| Observability | Unified message journal, delivery receipt and read metrics |
| Testing | Fault injection, chaos testing, contract tests for schemas, end-to-end replays |
A few items matter more than they might seem at first glance. Use stable message IDs and a de-duplication window to stop late duplicate sends across fallback channels. Keep consent rules in the checklist so a fallback path never slips past suppression rules. And centralize delivery state so retries, fallbacks, and failures stay visible in one place.
That last part is a big deal. When teams can see routing and delivery status in a unified inbox, this checklist gets much easier to use across channels.
Keep this checklist as the baseline for routing, fallback, and monitoring reviews.
FAQs
How do I choose the right fallback order?
Pick your fallback order based on message intent, budget, and what the recipient can actually receive. Don’t lock yourself into one fixed sequence for every message.
For urgent, time-sensitive messages like OTPs, put reach first. That often means SMS first. For promotional or low-priority content, lean toward the lower-cost option.
To route messages well:
- Skip channels the recipient can’t use
- Use time-based triggers
- For high-severity messages, consider sending across channels at the same time
- Use a routing layer that adjusts to device state, location, and past engagement
The idea is simple: the best fallback path depends on the situation, not a preset order.
What counts as a duplicate message?
A message is a duplicate when the same event, intent, or communication gets processed more than once. That can lead to repeated actions, or a customer experience that feels scattered and disconnected.
This usually happens after retries, timeouts, crashes before acknowledgment, or failovers. In support, it can also show up when the same customer issue turns into separate tickets across channels like email and chat.
To keep that under control, teams often use deduplication keys such as message IDs or idempotency keys.
Which metrics should I monitor first?
Start with transport health and operational reliability metrics.
First, track whether messages are getting through. That means watching SMS carrier acceptance, delivery receipt rates, failed submissions, email inbox placement, bounce rates, and spam complaints. If reach is weak, everything after that gets shaky.
Then keep an eye on the systems behind delivery: API latency, webhook success rates, and retry rates. These numbers help you spot delays, failed handoffs, and other issues that can make message delivery less predictable, especially for time-sensitive communications.